Different Residuals, Better Ensembles?
A tiny experiment in making gradient boosting models disagree on purpose by comparing ordinary additive residuals with multiplicative residuals - and checking whether a weaker multiplicative model can still improve a simple 50/50 ensemble.
4/29/20262 min read
Gradient boosting is usually described as a sequence of trees, where each new tree tries to correct the mistakes of the current model.
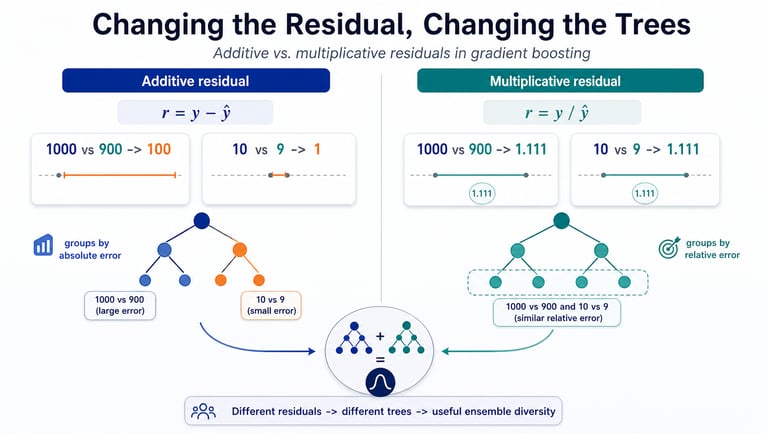
In the standard squared-error case, those mistakes are additive residuals:
r = y - y_hat
The next tree is trained to predict where the current model is too low or too high in absolute terms.
This has an interesting consequence: the way we define the residual also affects what the next tree sees as a “similar” mistake. Two observations with very different target values can be grouped together if their residuals look similar. Conversely, two observations with the same target value can be treated very differently if their residuals differ.
For example, with additive residuals, these two errors look very different:
target = 1000, prediction = 900 -> additive residual = 100
target = 10, prediction = 9 -> additive residual = 1
A standard gradient boosting tree will usually care much more about the first case, because the absolute error is larger.
But suppose we define the residual multiplicatively instead:
r = y / y_hat
Now the same two examples look identical:
target = 1000, prediction = 900 -> multiplicative factor = 1.111
target = 10, prediction = 9 -> multiplicative factor = 1.111
In both cases, the prediction is about 10% too low. So the next tree is being asked a different question. Instead of looking for groups of observations with similar absolute errors, it can look for groups with similar relative errors.
That is the core idea of this experiment:
Changing the residual changes the trees.
The point is not that multiplicative residuals are necessarily better than additive residuals. Multiplicative residuals are just one simple example. Other residual definitions could also be interesting: log-ratio residuals, signed-squared residuals, prediction-bin centered residuals, rank-based residuals, or hybrids between absolute and relative error.
The broader idea is to treat residual design as a way to create ensemble diversity. Different residual definitions can lead to different tree structures, which can lead to models that make different mistakes.
In the experiment, I compare three models on the California Housing dataset across multiple random seeds:
ordinary gradient boosting with additive residuals
a custom multiplicative residual boosting model
a simple 50/50 average of the two
The goal is not necessarily for the multiplicative model to beat ordinary gradient boosting on its own. In fact, it may be worse as a standalone model. The question is whether it makes different enough mistakes to become useful in an ensemble.
In other words:
Can we make gradient boosting models disagree on purpose, and can that disagreement improve a blend?
The full experiment is available in the notebook here: https://www.kaggle.com/code/ern711/changing-the-residual-changing-the-trees
I also posted a short discussion on Kaggle here: https://www.kaggle.com/discussions/general/696725