Hypernetworks: A Promising Way to Adapt Neural Networks
A simple introduction to hypernetworks, why I think they are interesting for controlled model adaptation, and how they can generate delta weights for a trained neural network.
7/4/20264 min read
This could make the adaptation more modular. One part of the model could be adapted based on one condition, while another part could be adapted based on a different condition.
This does not necessarily mean the model becomes better automatically. It could also make the system harder to train and harder to debug. But it gives us an interesting way to ask whether different parts of a model should adapt differently.
Why I find this promising
I do not think hypernetworks should be seen as a magic solution, or as something that is always better than normal fine-tuning. But I do think they are a useful idea to understand.
What I find interesting is that they give us another design pattern for model adaptation. Instead of treating a neural network as one fixed block of parameters, we can separate the base model from the mechanism that adapts it.
This opens up many possible directions. Hypernetworks could be used to generate only selected parts of a model, combine different feature sets, create more structured forms of adaptation, or work together with other fine-tuning methods.
Of course, not every idea will work well in practice. Some setups may be harder to train, harder to debug, or simply not better than simpler alternatives. But as a concept, I think hypernetworks are interesting because they make model adaptation feel more modular and controllable.
For me, that is what makes them promising.
In a future article, I may look at a small code example and show how to build a simple hypernetwork that generates delta weights for a trained neural network.
Hypernetworks are neural networks that generate the weights, or parts of the weights, for another neural network.
At first, that can sound a bit strange. Usually, when we train a neural network, the model learns its own weights directly. A hypernetwork changes this setup: instead of only learning a fixed set of weights, we train one network to produce weights for another network.
In other words, a hypernetwork does not necessarily make the final prediction itself. Instead, it helps create or adapt the model that makes the prediction.
A simple way to think about it is this:
A hypernetwork takes some input and produces weights for another neural network. The target network then uses those weights to make a prediction.
That is the basic idea. But what makes hypernetworks interesting to me is not only that they generate weights. It is that they offer a different way to think about model adaptation.
A simple visual intuition
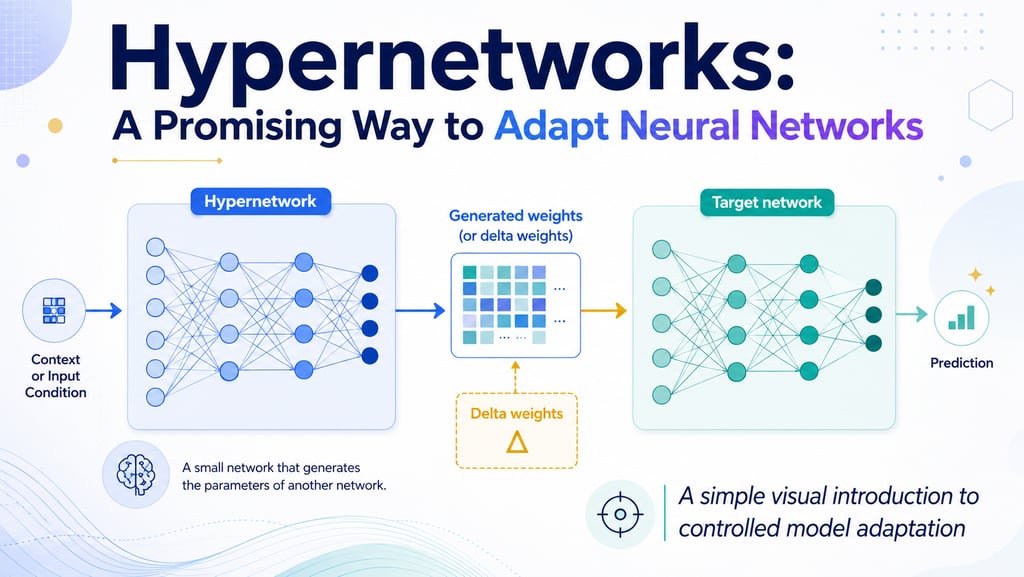
The basic setup can be shown as a simple flow: the hypernetwork receives some input, context, or feature set, and outputs generated weights or delta weights. These weights are then used by the target network, which makes the final prediction.
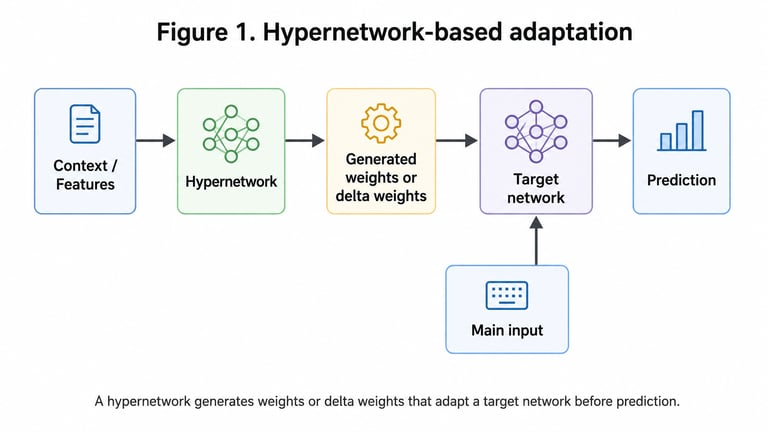
The important part is the separation of roles: the target network makes the prediction, while the hypernetwork helps decide how that network should be parameterized or adapted.
From fixed models to adaptable models
A normal neural network usually has one set of learned weights. If we want the model to behave differently for a new task, domain, or situation, we often need to retrain it or fine-tune it.
Hypernetworks give us another option.
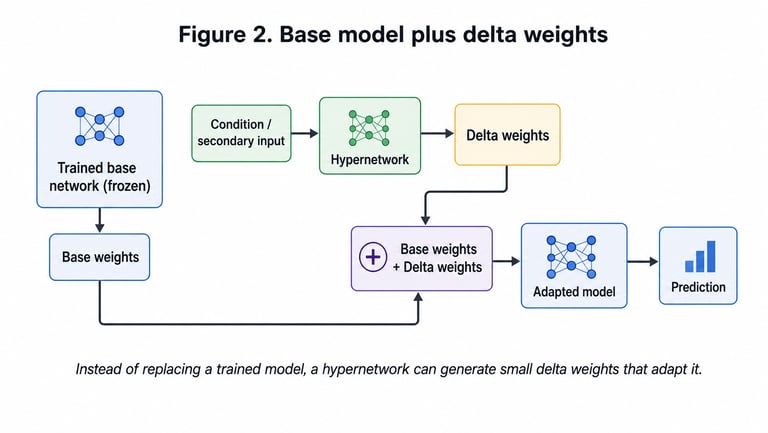
One practical version is to first train a normal neural network, freeze it, and then train a hypernetwork to generate delta weights. These delta weights are small adjustments added to the original weights of the trained model.
In simple terms:
adapted weights = base weights + generated delta weights
This is the part I find especially promising. The original model can remain mostly stable, while the hypernetwork learns how to adjust it.
Controlled flexibility
Hypernetworks do not only add flexibility. In some cases, they can also make that flexibility more structured.
For example, if a hypernetwork is much smaller than the target network, it can act as a bottleneck. It may still generate a large number of weights or delta weights, but those values are produced through a smaller model. The target network is therefore not being adapted by freely changing every parameter independently. The adaptation has to pass through the representation learned by the hypernetwork.
That can be useful because more flexibility is not always better. Sometimes we want a model to adapt, but not in a completely unconstrained way.
A hypernetwork can give us a middle ground: the base model can stay mostly stable, while the hypernetwork learns a structured way to modify it.
Different inputs for different roles
Another interesting aspect is that the hypernetwork does not need to use the same input features as the target network.
The target network might make predictions from one set of features, while the hypernetwork receives a different set of features and uses them to generate weights or delta weights. These features do not have to be metadata or high-level task information. They can simply be another view of the problem, or another signal that is useful for deciding how the target network should behave.
In that sense, the hypernetwork is not just adding more parameters. It gives us another way to control how the model behaves.
Multiple hypernetworks around one base model
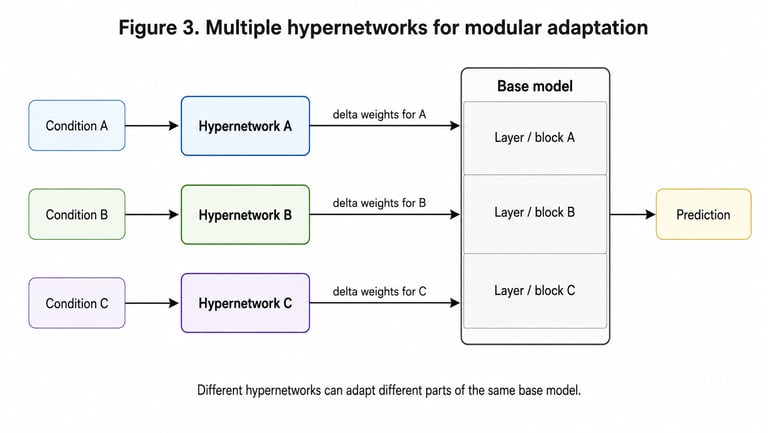
Another possible idea is to keep one trained base network and train multiple hypernetworks around it.
Each hypernetwork could learn to generate its own delta weights for the same base model. This would create several adapted versions of the original network without training several completely separate models from scratch.
In some settings, this could create something similar to an ensemble. The base model provides a shared foundation, while the different hypernetworks create variation by modifying it in different ways.
Of course, this does not automatically mean the result will be better than a normal ensemble or a fine-tuned model. But it is an interesting direction to explore, especially if the hypernetworks are trained with different data, feature sets, objectives, or constraints.
Adapting different parts of the network
A related idea is to let different hypernetworks be responsible for different parts of the target network.
For example, instead of having one hypernetwork generate all delta weights for the entire model, we could imagine several smaller hypernetworks where each one adapts a specific layer, block, group of neurons, or even individual neurons.