The Myth That a Large Train-Test Gap Means Overfitting
Why a large gap between training and test performance does not necessarily imply overfitting.
3/20/20262 min read
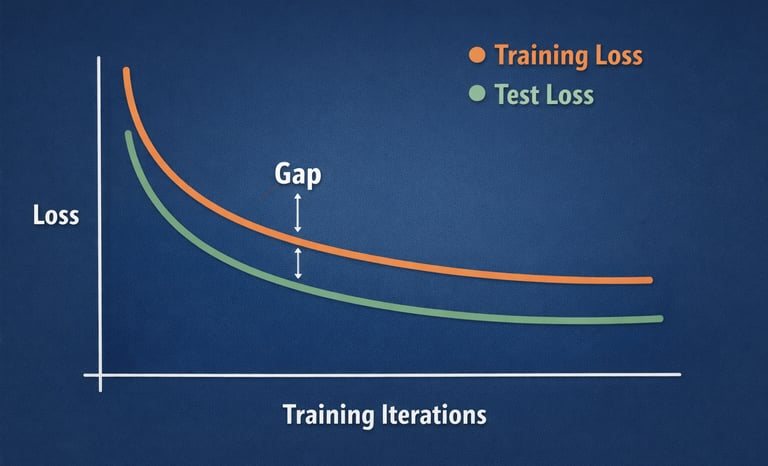
We’ve all heard it: if your model performs much better on the training set than on the test set, it must be overfitting. While this can be true, it’s not a logical implication, and treating it as one often leads to the wrong conclusions.
What’s more surprising is how often this claim shows up in professional settings, even among experienced practitioners.
Why this Is wrong
While a large performance gap can indicate overfitting, there is no such implication in general. There is nothing that guarantees that the training fit which yields the best generalization must result in similar performance on the training and test sets.
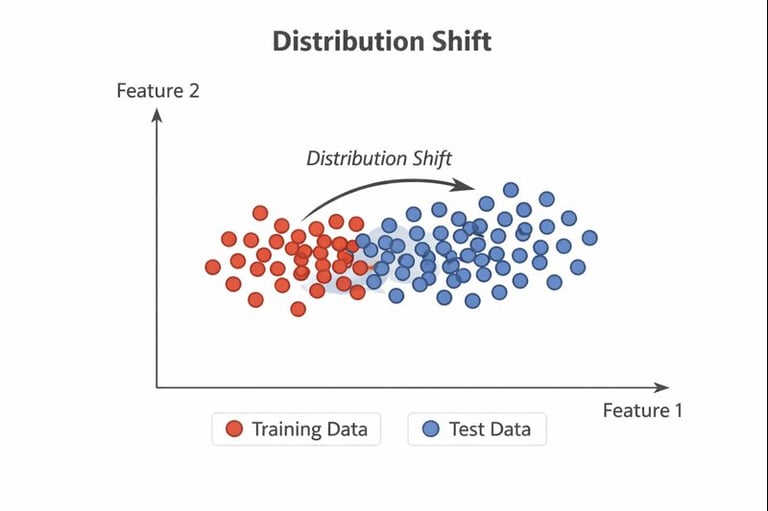
There are many ways to see this, but a particularly simple one is to consider the case where the data distribution has drifted significantly between training and testing. In that situation, it is almost guaranteed that performance on the test set will differ - most often be worse - than performance on the training set, even if the model represents the best possible fit to the training data.
An illustrative example of this is shown in the figure below:
Another important (and often overlooked) reason for a systematic train–test gap is how many models are actually trained, even in the absence of classical overfitting.
Take gradient boosting as an example. In standard implementations, the same data is used both to determine where to split the trees and to estimate the leaf values. This introduces an inherent bias: the model is, in a sense, evaluating its own decisions on the same data it used to make them. As a result, the training error is optimistically biased downward, even when the model generalizes as well as it possibly can.
This is closely related to the idea of honest boosting, where the data used to determine splits is separated from the data used to estimate leaf values. By decoupling these steps, we remove this source of bias and obtain more reliable estimates - typically at the cost of higher training error.
We’ll take a closer look at honest boosting, and why it matters in practice, in a separate article.
So what should we do instead?
The key is to be clear about what the test set represents. Rather than aiming for similar performance on training and test data, the goal should be to construct a test set that resembles the production data as closely as possible. Once that assumption is in place, model selection should be driven by performance on the test set alone, regardless of how large the gap to training performance may be.
Of course, this assumes that the evaluation setup is sound, and that the observed gap is not caused by data leakage, bugs, or inconsistencies between training and test data.
Takeaways
A large train–test gap is not evidence of overfitting by itself
Training error is often systematically optimistic due to how models are trained (e.g. gradient boosting)
The gap can arise even when the model generalizes well
Methods like honest boosting show that reducing bias can increase training error while improving reliability
The goal is not to minimize the train-test gap, but to evaluate on test data that reflects production
Model selection should be driven by test performance alone, not how close it is to training performance
Always rule out data leakage, bugs, and evaluation issues before interpreting the gap