Gradient Boosting with Honest Leaf Estimation
A minimal example showing how separating structure and leaf estimation makes training error less biased.
4/6/20261 min read
In the previous post (https://randomstate21.com/the-myth-that-a-large-train-test-gap-means-overfitting), we saw that part of the train - test gap in gradient boosting comes from how trees are trained - the same data is used both to determine splits and to estimate leaf values.
Here, we implement a simple variant where these steps are separated. Trees are grown on one subset of the data, while leaf values are estimated on another.
Below is a minimal implementation of gradient boosting with honest leaf estimation, using the California Housing dataset as a simple regression example. Model parameters are documented directly in the class docstring.
The code runs the same model in two modes - honest and non-honest - where the only difference is how leaf values are estimated. In both cases, we use a leaf fraction of 0.2, meaning that 20% of the data is reserved for leaf estimation and the remaining 80% for learning the tree structure. In the honest variant, leaf values are computed on this held-out subset, while in the non-honest variant they are effectively estimated from the same data used to grow the tree.
The implementation below includes a few additional features and safeguards, but these are not essential for the example - the key idea is the separation between structure and leaf estimation:
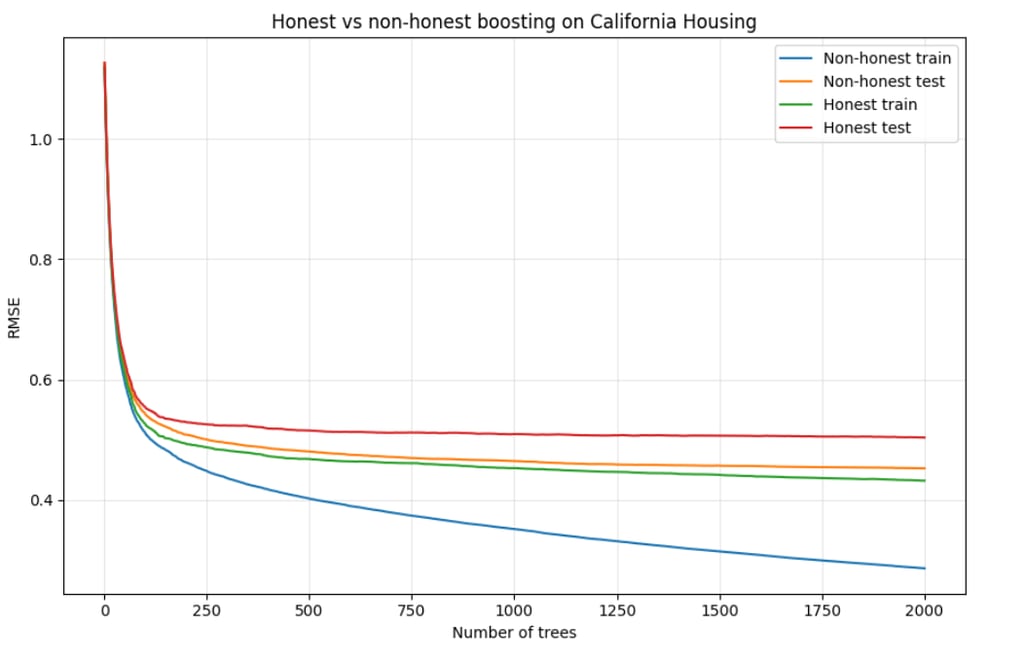
The resulting train and test RMSE curves are shown below:
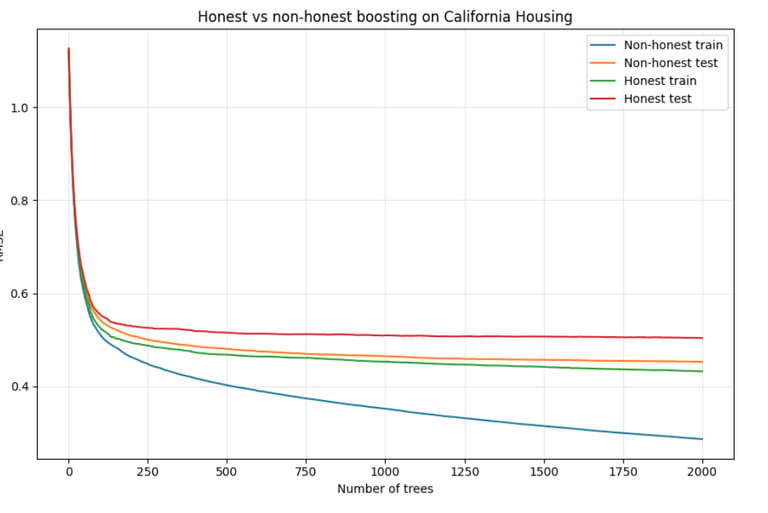
As expected, the gap between training and test RMSE is smaller in the honest variant than in the non-honest one.
The point here is not which model performs better, but to illustrate how the training procedure itself affects the train-test gap. The honest variant produces a less optimistic training error - and therefore a more meaningful comparison to test performance.
We then track how train and test RMSE evolve as trees are added: